从声波采集到AI辅助诊断——看智能硬件如何将“心跳呼吸”转化为精准数据流
无线AI智能听诊器并非简单地将传统听诊器“无线化”,而是一套完整的“采集-放大-传输-分析-可视化”闭环系统。
它利用MEMS声学传感、低噪声放大、双模无线通信、本地+云端AI声纹识别等技术,将人体内部的微弱生理声信号转化为客观、可视化的诊断数据,彻底摆脱对医生听觉经验的过度依赖。
以下按照信号流向,逐步拆解其核心工作原理。
一、前端采集:MEMS麦克风如何“听见”身体的声音
探头接触患者体表后,人体内心脏搏动、呼吸气流、瓣膜开合等产生的机械振动通过组织传导至探头声腔。
核心传感器采用MEMS麦克风(型号SMM310),其内部有一个微型振膜和背极板,声压变化引起振膜形变,从而改变电容,最终转换为电信号。
该麦克风灵敏度极高,频率响应覆盖20Hz – 20kHz,完整涵盖心音(20-200Hz为主)、呼吸音(100-1000Hz)及部分高频杂音。
同时,MEMS结构具有优异的抗射频干扰能力,可在心电监护、手机信号等复杂电磁环境中稳定工作。
此外探头内集成了高精度温度传感器,通过接触式或非接触式红外原理同步采集体温,实现“一听一测”多功能融合。
二、精密放大:AD8510实现0.0005%超低失真
MEMS麦克风输出的原始电信号幅度极小(微伏至毫伏级),必须经过高保真放大。
探头采用AD8510精密运算放大器,其关键特性为极低失真(典型失真度仅0.0005%)和低噪声(4.0 nV/√Hz)。
这意味着放大后的信号几乎完美还原原始声波形态,不会引入额外谐波或背景嘶声。
放大倍数经过精密校准,确保不同患者体型、不同听诊位置都能获得稳定的信号强度,同时避免饱和失真。
经过放大后的模拟信号随即通过ADC(模数转换器,集成于主控芯片内部)转换为数字音频流,采样率通常设置为44.1kHz或更高,满足AI分析所需的时域和频域细节。
三、无线传输:WiFi + 蓝牙5.0双模低功耗链路
主控芯片乐鑫ESP32-S3集成了WiFi 802.11 b/g/n和蓝牙5.0(LE Audio)双模射频。
在门诊、查房场景中,默认开启蓝牙5.0传输,功耗极低且可直连接收主机(平板或专用终端),有效传输距离10-20米;对于需要高保真未压缩音频或远程会诊时,可切换至WiFi模式,利用医院无线网络将多路患者数据传输至服务器。
协议层面采用自定义数据包格式,包含音频帧、体温值、设备ID和时间戳,并具备前向纠错和重传机制,确保信号不丢包,不影响诊断准确性。
探头内置纽扣电池,ESP32-S3支持深度休眠模式,无听诊动作时自动待机,功耗仅为传统蓝牙方案的1/3,换一次电池可满足连续数小时高强度使用或数天的间歇使用。
四、接收主机:双处理器分工协同
接收主机内部采用ESP32 + 瑞芯微RK3568双处理器架构。
ESP32负责无线数据接收、协议解析和音频流缓冲,并将数据通过高速内部总线传输给RK3568。
RK3568是一颗四核ARM Cortex-A55处理器,集成GPU和NPU(神经网络处理单元),专门负责AI推理、波形渲染和显示交互。
这种分工避免了单芯片的资源竞争,确保实时音频处理和复杂AI模型并行运行无延迟。
接收主机配备大容量锂电池和快速充电电路,充满后可连续工作8-10小时,满足全天临床使用。
数据存储同时支持eMMC本地存储(存储数千条听诊记录)和云同步,方便后续回顾与病历整合。
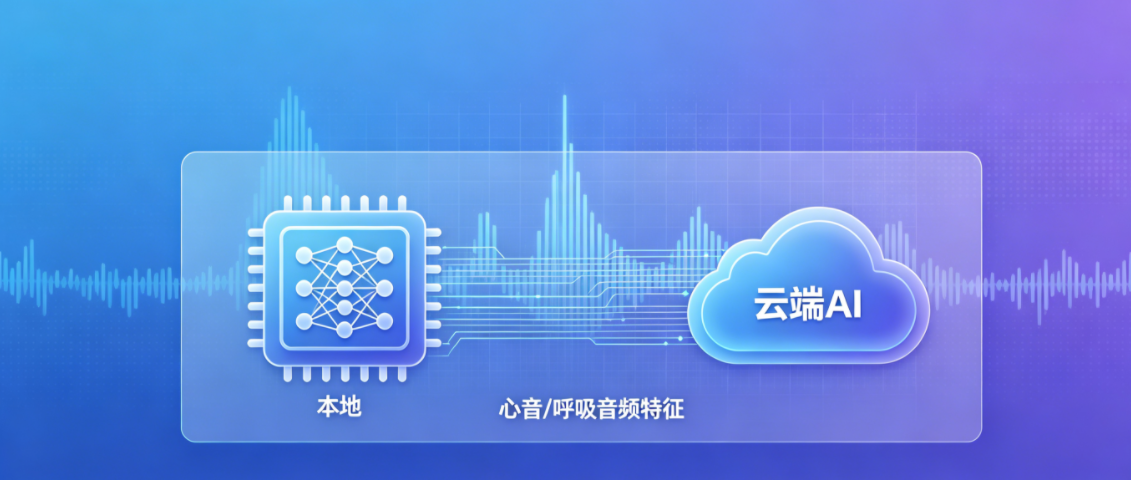
五、AI声纹识别:从声音到诊断的“智慧大脑”
AI分析是整个工作原理的核心环节。RK3568内置的NPU或调用云端算法运行深度神经网络模型。具体流程如下:
- ① 预处理 — 将音频流分帧(典型帧长25ms)、加窗,提取MFCC(梅尔频率倒谱系数)、频谱特征等声学参数。
- ② 本地模型推理 — 主机内置轻量化卷积神经网络(CNN)或循环神经网络(RNN),模型经过上万份标注心音、肺音训练,可实时分类识别正常心音、早搏、房颤、哮鸣音、湿啰音等。本地推理延迟<2秒,无网络时仍可提供辅助诊断。
- ③ 云端增强分析 — 当连接互联网且需要更精准判读复杂病例时,可将去隐私化的音频特征上传至云端服务器,利用更大规模的深度残差网络(ResNet)和百万级声纹库进行二次比对,输出置信度更高的诊断建议,同时返回详细的异常部位热区图。
- ④ 异常标注与参考结论 — 最终输出文本提示,如“可疑S3奔马律,建议心脏超声”或“呼气相细湿啰音,提示肺炎早期”,医生可根据自身经验进一步确认。
这种本地+云端双模机制兼顾了实时性与诊断深度,是AI听诊器区别于传统电子听诊器的关键技术跃升。
六、可视化呈现:将声音变成波形与数值
接收主机的8英寸高清液晶屏实时渲染音频波形(时域波形 + 频谱图)。
波形刷新率与音频采样同步,医生可直观看到心电样式的周期性波形,通过波幅、间距快速判断节律整齐性、杂音位置。
同时界面叠加显示AI标注的异常时间段(例如用红色条带标记可疑杂音)、体温数值及诊断置信度。
所有数据支持触控缩放、测量波峰间隔,进一步满足临床深度分析需求。
存储方面,每次听诊生成一个结构化记录:包含原始音频文件(压缩格式)、波形截图、AI结论、时间戳、患者ID(匿名化)。
本地存储至少保存1000条记录,云端永久存储且支持多终端同步,为远程会诊和科研教学提供完整数据资产。
工作流程闭环总结
患者体表声音 → MEMS麦克风(声电转换)→ AD8510放大器(低失真放大)→ ESP32-S3(ADC+双模无线发送)→ 接收主机ESP32(接收缓冲)→ RK3568(AI声纹识别 + 波形渲染)→ 可视化界面与AI参考诊断 → 本地/云端存储 → 医生结合经验做出最终临床决策。
整个链路中,无线技术打破了肢体接触的物理限制,AI则突破了人类听觉的主观瓶颈,让听诊成为真正的“数据驱动诊断工具”。
⚙ 无线AI智能听诊器 | 声-电-数-智 全链路解析
@2026 华垓技术 | 专注于高精尖仪表 / 设备电控解决方案


 扫一扫咨询微信客服
扫一扫咨询微信客服